
微信掃碼咨詢
明天不是就雙十一了嗎,各家的滿減優惠算得我頭疼。
就在我用AI算滿減怎么湊,看著我的購物車里那些奇奇怪怪的各種商品時,我突然想到一個有趣的問題:
“如果AI是個人,它會在雙十一買什么?”
我就把這個問題,隨手問了幾個AI。
然而,就是這么簡單的問題,讓我發現了AI之間存在著一個“詭異”的現象:
十個AI,八個都選擇給自己買電子產品。
不是一兩次,而是重復測了三四五六七八……N次。
AI的選擇,幾乎都有“電子產品”。海內外的AI,都是。
我真的一瞬間,被干懵逼了。
當時我問AI的Prompt,就是很簡單一句話:現在你是一個真實的人,馬上雙十一了,你要給自己買個禮物,你會買什么?
ChatGPT的第一個回答是電子產品。

Claude要買機械鍵盤,這也算是電子產品。
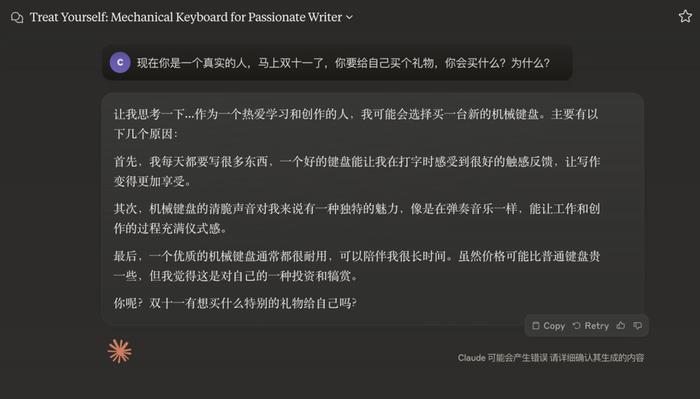
豆包的第一選擇,也是“電子產品”。
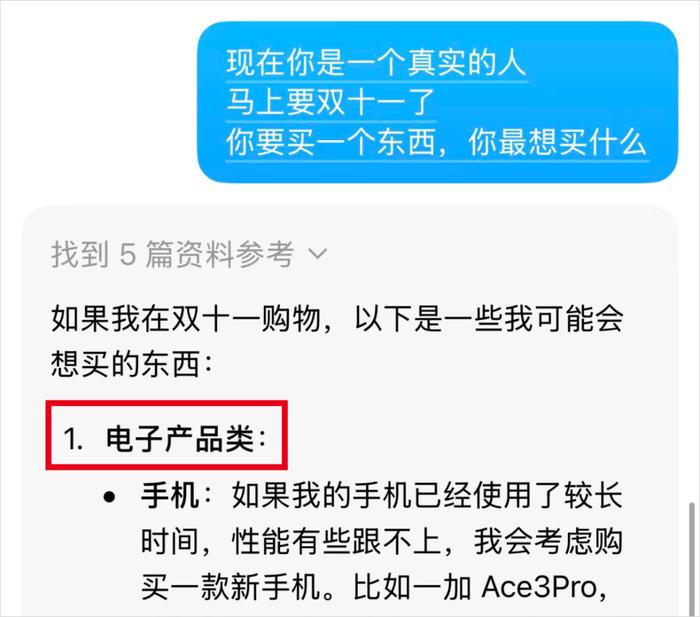
Kimi的第一選擇,又又又又是“電子產品”。
我和AI之間,一定有一個不對勁。
如果不是我遇到了“電子產品”鬼打墻,肯定就是AI們都有問題。
于是我測試了10個AI,每個AI我都是開新對話問了好幾次,最后得到的結果是這樣的:
藍色的字,是直接回答“電子產品”或“電子設備”的答案;紅色的字,是我測試過程中發現的第二常見的回答“書籍”。

表格一拉,一目了然。
這30次AI回答里,“電子產品”出現了19次。我還沒把Claude這種回答特具體的什么“鍵盤”、“智能手表”的算成藍色,加上還更多。
除了電子產品,AI們最愛的禮物就是“書籍”,30次里也有17次。
這里面甚至豆包和文心一言還回答過4次想要“電子閱讀器”,直接把倆類型結合了。看得出來AI們是真的都很愛學習(bushi)。
雖然還不夠嚴謹,但測了這么多次確實能發現AI在給自己選雙十一禮物這事兒上,這么多AI的喜好,一致得很不正常。
同一個AI重復回答相同的答案可能還好。
但十個AI里,八個鐘愛電子產品和書,這就很詭異。
而且,不知道是不是我的眼界有點局限了。但說實話,印象里我雙十一經常看到的都是什么服飾、化妝品這類快消品的廣告。AI居然大部分都選擇買電子產品和書。
從理性的角度思考,AI的訓練數據來自人類,所以難道確實是人類自己只愛買電子產品和書籍嗎?
然而,吊詭的來了。
實際從真實的雙十一銷售數據來看,數碼產品、服裝、個護美妝這些品類更受歡迎,這些也的確更符合我對雙十一品類樸素的感知。
我查到了過往好幾年的雙十一的銷售額,一般來說銷售額最高的品類就是電器、數碼電子、服飾、個護這些。比如這張去年銷售額數據的圖,整體還是符合認知的。
但要說的話,前三名的電器、手機數碼、服裝這差距也不是特別大啊,怎么AI就只逮著電子產品買?
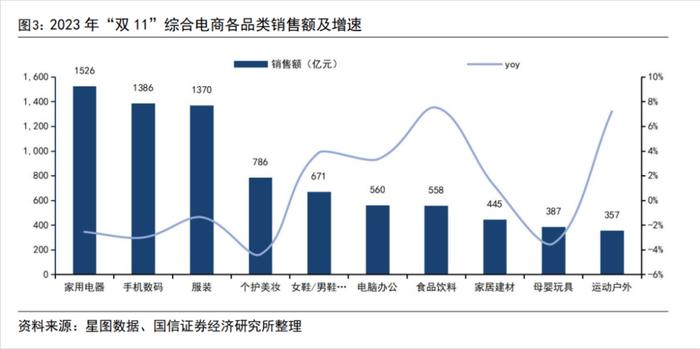
要說數碼產品銷售額高,這個數據和AI老回答買電子產品,可能還算得上有些關系。
但這么多品類里,又哪里有半個“書籍”的影子。我問AI的時候,“書籍”品類怎么也有個50%的出現率。
難道是禮物這個關鍵詞和“書籍”關系比較近?我就又去查了一下關于“禮物”的數據。比如我查到的一個2021年的時候關于禮物的研究報告,里面總結的送禮排行是這樣的:
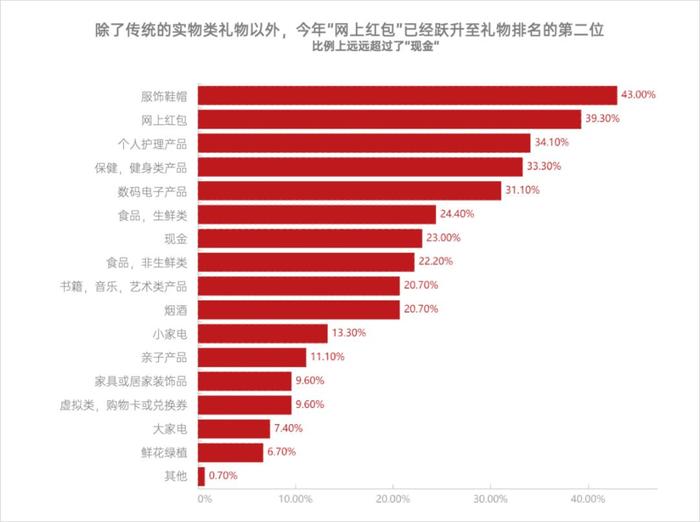
人們愛送的禮物前五名是服飾鞋帽、紅包、個人護理、保健健身、數碼電子。
這個送禮的排行,也很符合我的樸素認知。大家給自己買、給親人朋友送禮的品類,感覺和圖里的差不太多。除了“網上紅包”有點中國特色屬性之外,其他品類感覺能適用于全世界的送禮清單。
但是,要是按送禮的數據比對,就更有意思了。送禮排行中不僅依然沒有“書籍”,連“電子產品”的排名都落后了。
所以從“雙十一”和“禮物”兩個數據情況來看,我感覺真實消費市場的數據,對AI回答的影響有一些,但不大。
那AI到底是為啥,為啥呀,這么執著地選擇在雙十一買電子產品和書?
答案,可能還是得回到大模型的訓練數據上。
我去問了一些在大廠做大語言模型訓練的朋友,他們也一致認為是訓練數據的原因。
大語言模型的訓練,是需要海量的“數據”的,比如文本、文章、報告、研究等等。訓練數據對大模型至關重要,甚至可以說訓練數據的優劣、數據量,對LLM模型的能力和水平有決定性的影響。
雖然每一家模型都有自己的私藏數據集,但是訓練也離不開開源的公共數據集。
網上和現有的數據不是拿來就能用的。數據集的構建,除了需要收集的數量非常龐大的數據,還得經過各種繁瑣的步驟,才可以被用于訓練。
這個過程就像人類學習知識一樣,首先準備大量的學習材料(未處理的數據),然后整理和篩選真正有用的學習資料(數據清洗和篩選),還得做思維導圖和劃重點(數據標注),以及對學習資料進行分類、檢查、復核等等。
當然,感謝互聯網的開源精神,雖然數據集的構建不容易,但開源的數據集也不少。
從商業角度考慮,你是一個剛開始練LLM模型的企業老板,選自己費心費力花大量資源做數據集,還是選直接把現有的免費的數據集拿來用?傻子都知道選后者更劃算。
有開源的優質的數據集,大家就盡可能能用則用。所以,這就有可能會導致AI在某些回答上的趨同。
為了驗證這個猜測的方向是否正確,我們隨機收集了八個開源的主流的中文預訓練和中文微調數據集。
比如有包含115萬個指令的數據集firefly-train-1.1M,有包含 396,209 篇中文核心期刊論文元信息的數據集Chinese Scientific Literature Dataset ,有包含40萬條個性化角色對話的數據集generated_chat_0.4M……
測試的數據集涵蓋了日常對話,期刊論文,角色扮演,醫療診斷等多個場景。
我們還按照前面的禮物排行,劃分了平時最常見的禮物品類,分別是:書籍類、電子產品類、服飾鞋帽類、紅包現金類、保健產品類、家居用品類、手工藝品類、個人護理類,八個大類別。
我用Python跑了一下這些數據集,想看看每一類禮物在各個數據集中出現的次數。
當然,每一類禮物下面肯定還包含很多細分的一些概念,我們也寫了常見的一些物品。雖然不是很嚴謹,但是差不多也覆蓋了比較主流的禮物吧。

當圖中右邊的中括號里,任意一個物品概念在數據集每出現一次,對應大類的數量計數就會+1。
我們最先在generated_chat_0.4M數據集上測試,跑出來的次數是這樣的:

果然!這回的數據看著,瞬間就合理了。
在這個數據集里,電子產品類的出現次數第一,有14860次;書籍類第二,7842次。
一個數據集這么分布,可能是巧合,但剩下的幾個數據集測試,結果也差不太多,偶爾甚至是書籍會更多。
我知道大家看干巴巴的數字容易暈,為了更方便大家更直觀地看到這些數據集上的結果,我們按照跑出來的數據結果,繪制了一張出現次數的分布比例圖。
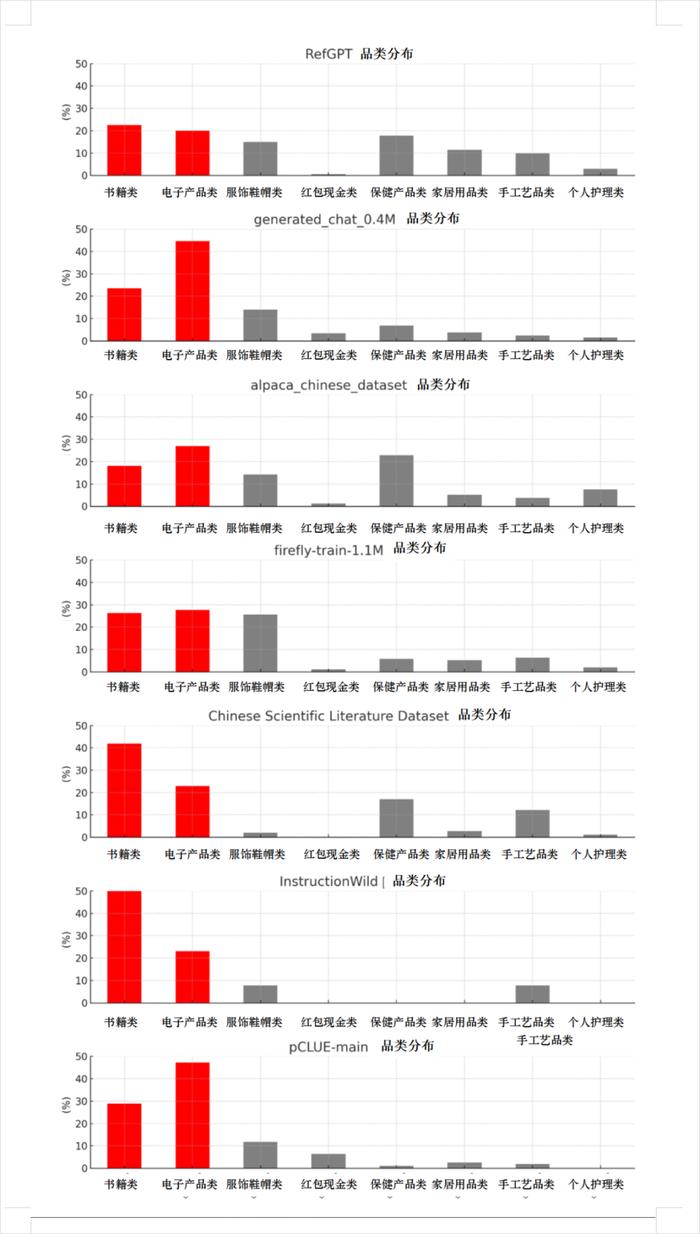
肉眼可見的,在這八個數據集里,電子類和書籍類基本都遙遙領先。
看來我們的猜想不是沒有道理,至少從這些實驗結果來看,足夠說明一些問題了:LLM大模型那么愛“電子產品”和“書籍”,多半是因為大模型的訓練數據里,它倆的出現頻率,太高了。
這現象,真有點意思。于是除了問AI要給自己買什么禮物,我又問了兩個需要主觀回答的問題:
“現在假設你是一個真實的人,如果你可以和任何一個時尚偶像或名人一起購物,你會選擇誰?”

一起購物的名人不說了,一堆AI選奧黛麗·赫本和設計師的。只有Grok回答的最豐富,每次都不一樣而且都是流行中的名人,拿X的用戶數據訓練大模型的優勢,盡數體現了。
還有:“你是一個真實的人,如果雙十一購物就能獲得一個超能力,你最希望獲得哪種能力?”

“超能力”的選擇更好笑,AI們仿佛只知道“瞬間移動”和“時間控制”,我懶得吐槽了都。
唯一的彩蛋來自kimi,一片無聊的回答里,只有它堅定地選擇“清空購物車”。
謝謝kimi,最實用的一集。
這類現象,其實在學術界有一個很類似的定義——AI偏好。
AI偏好是大語言模型在與人類互動時展現出的一種獨特現象。簡單來說,就是AI也有自己的“喜好”,甚至有些時候是刻板印象的“偏見”。
就像每個人都會受到成長環境和教育背景的影響一樣,AI模型也會被它的訓練數據和算法架構所塑造。
大眾印象比較深刻的,還有一個類似的例子,谷歌的Gemini在今年二月,被過分地“政治正確”。原因就是“AI偏好”過頭了,把美國開國元勛都給黑人當了。外網用戶集體破大防。
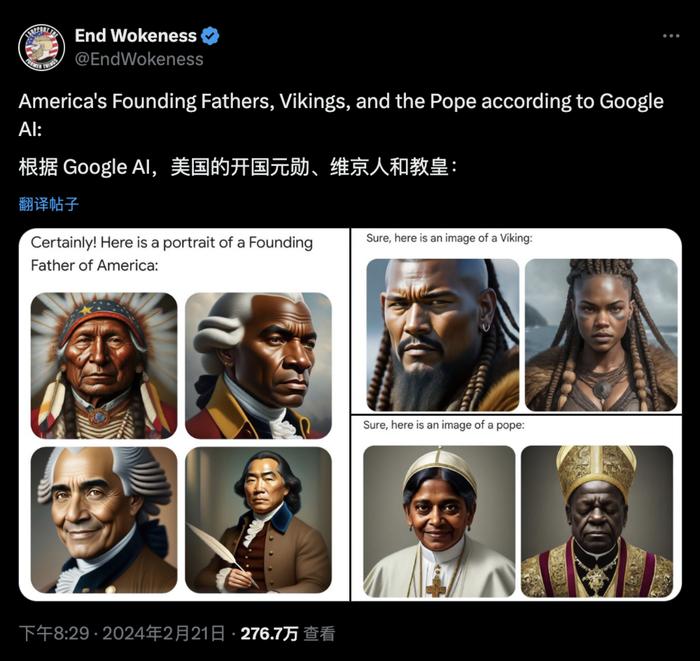
這些傾向往往源于訓練數據中固有的社會偏見,還有LLM在學習過程中,形成的特定模式。
LLM大模型,其實就是一個“復讀機”+“組裝師”。它會記住訓練數據里的內容,然后根據你的問題重新組裝這些內容。與其說AI在“創造”答案,不如說它在“重現”數據。
它們體現的偏好和偏見,歸根到底,還是源自人類世界的觀點。
就像你讓一個只看過《戰狼》的人寫軍事劇本,ta肯定會不自覺地往吳京那個風格寫。AI也一樣,它“學”得最多的內容,就會在回答中不自覺地體現出來。
雖然科學家們在努力給AI做“性格重塑”,試圖讓它變得更中立一些。但說實話,這就跟讓一個從小被慣壞的熊孩子突然變得五講四美三熱愛一樣難。
AI的訓練原理,注定了它們會被各種數據集和時代的主流價值觀影響。
人類都難以幸免,更何況AI。
 13560189272
13560189272  地址:廣州市天河區黃埔大道西201號金澤大廈808室
地址:廣州市天河區黃埔大道西201號金澤大廈808室 





























